ข่าว
อาลีบาบา คลาวด์ เปิดตัว Qwen2.5-Omni-7B โมเดล AI มัลติโมดอล รองรับข้อมูลหลากหลายรูปแบบ
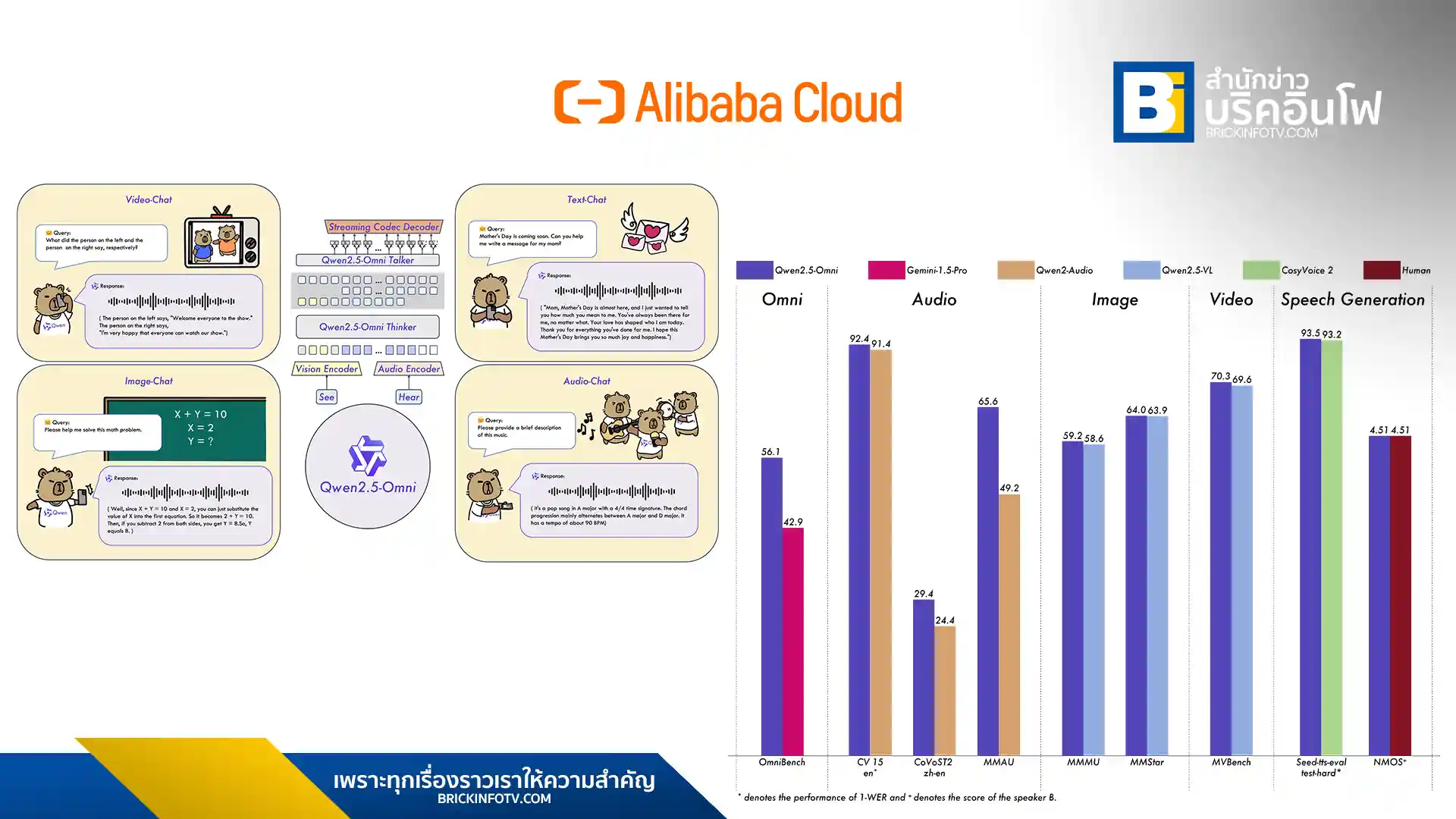
สำนักข่าวบริคอินโฟ – อาลีบาบา คลาวด์ (Alibaba Cloud) ได้เปิดตัวโมเดลปัญญาประดิษฐ์ (AI) รุ่นล่าสุด Qwen2.5-Omni-7B ซึ่งเป็นโมเดลแบบมัลติโมดอล (multimodal model) ที่สามารถประมวลผลข้อมูลได้หลากหลายรูปแบบ ไม่ว่าจะเป็นข้อความ รูปภาพ เสียง และวิดีโอ โดยสามารถสร้างการตอบสนองได้ทั้งในรูปแบบข้อความและเสียงพูดแบบเรียลไทม์
โมเดล Qwen2.5-Omni-7B มีขนาดพารามิเตอร์ 7 พันล้านพารามิเตอร์ และได้รับการออกแบบมาให้สามารถใช้งานได้อย่างมีประสิทธิภาพบนอุปกรณ์ปลายทาง (edge devices) เช่น โทรศัพท์มือถือและแล็ปท็อป ทำให้สามารถนำไปประยุกต์ใช้ในแอปพลิเคชันที่หลากหลาย เช่น การช่วยเหลือผู้พิการทางสายตาด้วยการอธิบายสภาพแวดล้อมด้วยเสียงแบบเรียลไทม์ การให้คำแนะนำการทำอาหารโดยวิเคราะห์ส่วนผสมจากวิดีโอ หรือการให้บริการลูกค้าอัจฉริยะที่สามารถเข้าใจความต้องการของลูกค้าได้
อาลีบาบา คลาวด์ ได้เปิดให้ใช้งานโมเดล Qwen2.5-Omni-7B ในรูปแบบโอเพนซอร์สบนแพลตฟอร์ม Hugging Face และ GitHub รวมถึงผ่าน Qwen Chat และ ModelScope ซึ่งเป็นชุมชนโอเพนซอร์สของอาลีบาบา คลาวด์ โดยทางบริษัทได้เปิดตัวโมเดล Generative AI มากกว่า 200 โมเดลในรูปแบบโอเพนซอร์สในช่วงไม่กี่ปีที่ผ่านมา
โมเดล Qwen2.5-Omni-7B มีประสิทธิภาพที่โดดเด่นในทุกรูปแบบข้อมูล โดยมีประสิทธิภาพเทียบเท่ากับโมเดลแบบโหมดเดียว (single-modality models) ที่มีขนาดใกล้เคียงกัน โดยเฉพาะอย่างยิ่งในด้านการโต้ตอบด้วยเสียงแบบเรียลไทม์ การสร้างเสียงพูดที่เป็นธรรมชาติ และการทำตามคำสั่งเสียงแบบครบวงจร
ประสิทธิภาพของโมเดลนี้มาจากสถาปัตยกรรมที่ล้ำสมัย ซึ่งรวมถึง Thinker-Talker Architecture ที่แยกการสร้างข้อความและการสังเคราะห์เสียงออกจากกัน TMRoPE (Time-aligned Multimodal RoPE) ซึ่งเป็นเทคนิคการฝังตำแหน่งเพื่อซิงโครไนซ์อินพุตวิดีโอด้วยเสียง และ Block-wise Streaming Processing ที่ช่วยให้การตอบสนองด้วยเสียงมีความรวดเร็วและหน่วงต่ำ
โมเดล Qwen2.5-Omni-7B ได้รับการฝึกฝนล่วงหน้าด้วยชุดข้อมูลที่หลากหลายเพื่อให้สามารถทำงานกับข้อมูลทุกรูปแบบได้อย่างมีประสิทธิภาพ โดยมีประสิทธิภาพเทียบเท่ากับการป้อนข้อมูลเป็นข้อความล้วน ๆ ในงานที่เกี่ยวข้องกับข้อมูลหลายรูปแบบ
นอกจากนี้ โมเดล Qwen2.5-Omni-7B ยังมีความสามารถในการสร้างคำพูดที่ยอดเยี่ยม และสามารถสร้างคำพูดผ่านการเรียนรู้เชิงบริบท (in-context learning: ICL) ได้อย่างมีประสิทธิภาพ หลังจากได้รับการเสริมประสิทธิภาพด้วยการเรียนรู้แบบเสริมกำลัง (reinforcement learning: RL) โมเดลนี้แสดงให้เห็นถึงความเสถียรในการสร้างคำพูดที่เพิ่มขึ้นอย่างมาก
อาลีบาบา คลาวด์ ได้เปิดตัวโมเดล Qwen2.5 ในเดือนกันยายน พ.ศ. 2567 และ Qwen2.5-Max ในเดือนมกราคม พ.ศ. 2568 และได้รับการจัดอันดับที่ 7 บน Chatbot Arena นอกจากนี้ บริษัทยังได้เปิดตัว Qwen2.5-VL และ Qwen2.5-1M เพื่อรองรับการทำความเข้าใจภาพและจัดการกับข้อมูลบริบทที่ยาวขึ้น









